-
Balancing Kafka on JBOD

At Automattic we run a diverse array of systems and as with many companies Kafka is the glue that ties them together; letting us to shuffle data back and forth. Our experience with Kafka have thus far been fantastic, it’s stable, provides excellent throughput, and the simple API makes it trivial to hook any of our systems up to it.…
-
Log Analysis With Hive

At Automattic we see over 131M unique visitors per month from the US alone. As part of the data team we are responsible for taking in the stream of Nginx logs and turning them into counts of views and unique visitors per day, week, and month on both a per blog and global basis. To…
-
Building a Faster ETL Pipeline with Flume, Kafka, and Hive
Building a Faster ETL Pipeline with Flume, Kafka, and Hive
-
Elasticsearch StatsD Plugin
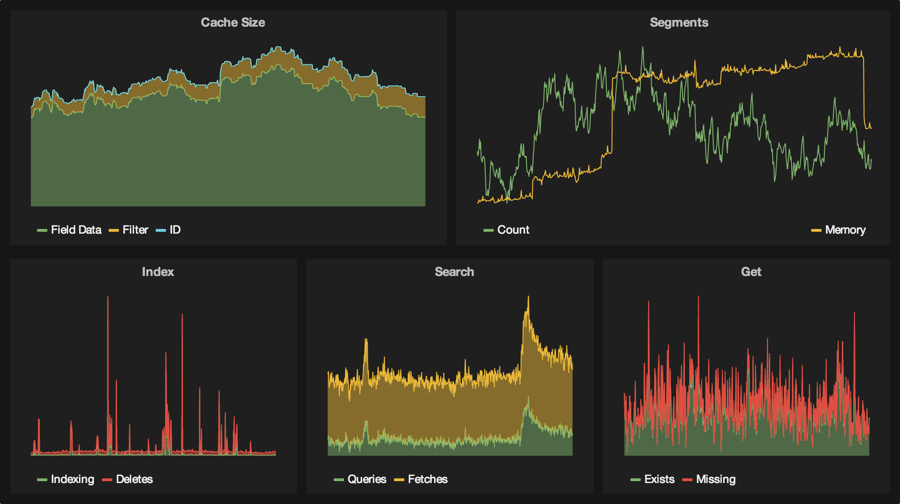
If you’re running a multi-node Elasticsearch cluster checkout Automattic’s fork of the Elasticsearch StatsD Plugin for pushing cluster and node metrics to StatsD.
-
Introducing Whatson, an Elasticsearch Consulting Detective
Over the past few months I’ve been working with the Elasticsearch cluster at Automattic. While we monitor longititudinal statics on the cluster through Munin when something is amiss there’s currently not a good place to take a look and drill down to see what the issue is. I use various Elasticsearch plugins however they all…